带你认识CPU缓存:了解CPU缓存的工作原理和作用

CPU高速缓存集成于CPU的内部,其是CPU可以高效运行的成分之一,本文围绕下面三个话题来讲解CPU缓存的作用:
为什么需要高速缓存?
高速缓存的内部结构是怎样的?
如何利用好cache,优化代码执行效率?
为什么需要高速缓存?在现代计算机的体系架构中,为了存储数据,引入了下面一些元件
1.CPU寄存器
2.CPU高速缓存
3.内存
4.硬盘
从1->4,速度越来越慢,价格越来越低,容量越来越大。这样的设计使得一台计算机的价格会处于一个合理的区间,使得计算机可以走进千家万户。
由于硬盘的速度比内存访问慢,因此我们在开发应用软件时,经常会使用redis/memcached这样的组件来加快速度。
而由于CPU和内存速度的不同,于是产生了CPU高速缓存。
下面这张表反应了CPU高速缓存和内存的速度差距。
存储器类型
时钟周期
L1 cache
4
L2 cache
11
L3 cache
24
内存
167
通常cpu内有3级缓存,即L1、L2、L3缓存。其中L1缓存分为数据缓存和指令缓存,cpu先从L1缓存中获取指令和数据,如果L1缓存中不存在,那就从L2缓存中获取。每个cpu核心都拥有属于自己的L1缓存和L2缓存。如果数据不在L2缓存中,那就从L3缓存中获取。而L3缓存就是所有cpu核心共用的。如果数据也不在L3缓存中,那就从内存中获取了。当然,如果内存中也没有那就只能从硬盘中获取了。
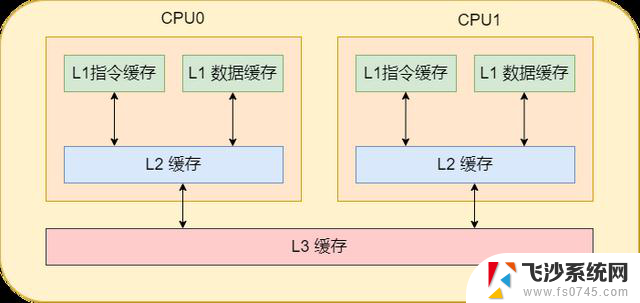
对这样的分层概念有了了解之后,就可以进一步的了解高速缓存的内部细节。
高速缓存的内部结构CPU Cache 在读取内存数据时,每次不会只读一个字或一个字节,而是一块块地读取,这每一小块数据也叫CPU 缓存行(CPU Cache Line)。这也是对局部性原理的运用,当一个指令或数据被拜访过之后,与它相邻地址的数据有很大概率也会被拜访,将更多或许被拜访的数据存入缓存,可以进步缓存命中率。
cache line 又分为多种类型,分别为直接映射缓存,多路组相连缓存,全相连缓存。
下面依次介绍。
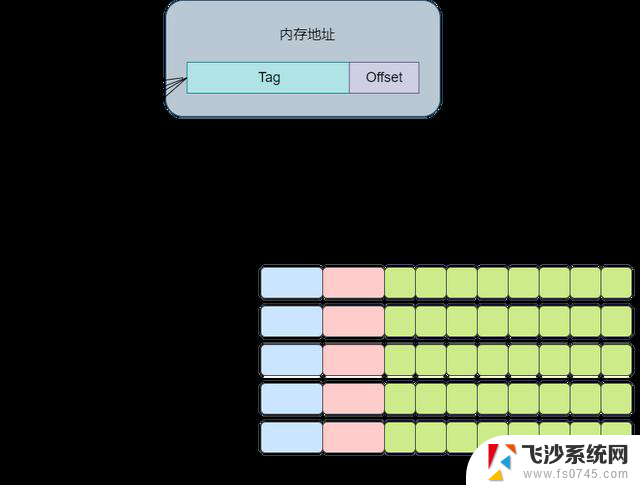
直接映射缓存直接映射缓存会将一个内存地址固定映射到某一行的cache line。
其思想是将一个内存地址划分为三块,分别是Tag, Index,Offset(这里的内存地址指的是虚拟内存)。将cacheline理解为一个数组,那么通过Index则是数组的下标,通过Index就可以获取对应的cache-line。再获取cache-line的数据后,获取其中的Tag值,将其与地址中的Tag值进行对比,如果相同,则代表该内存地址位于该cache line中,即cache命中了。最后根据Offset的值去data数组中获取对应的数据。整个流程大概如下图所示:
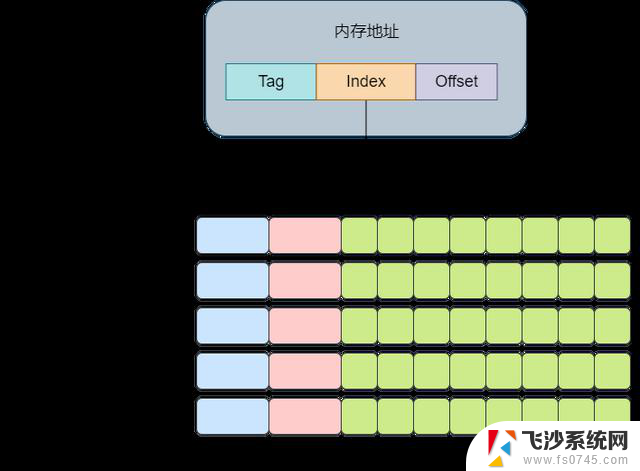
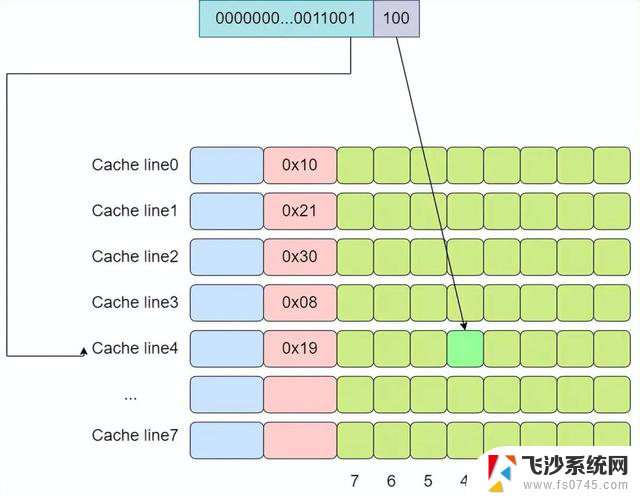
下面是一个例子,假设cache中有8个cache line,
对于直接映射缓存而言,其内存和缓存的映射关系如下所示:
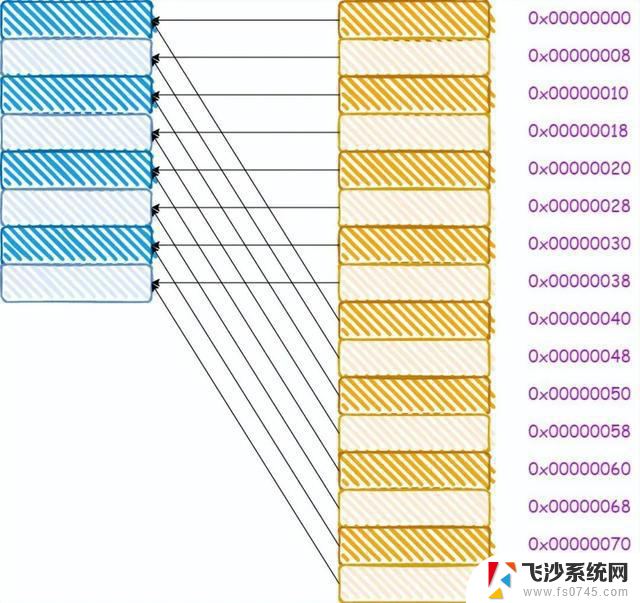
从图中我们可以看出,0x00,0x40,0x80这三个地址,其地址中的index成分的值是相同的,因此将会被加载进同一个cache line。
试想一下如果我们依次访问了0x00,0x40,0x00会发生什么?
当我们访问0x00时,cache miss,于是从内存中加载到第0行cache line中。当访问0x40时,第0行cache line中的tag与地址中的tag成分不一致,因此又需要再次从内存中加载数据到第0行cache line中。最后再次访问0x00时,由于cache line中存放的是0x40地址的数据,因此cache再次miss。可以看出在这个过程中,cache并没有起什么作用,访问了相同的内存地址时,cache line并没有对应的内容,而都是从内存中进行加载。
这种现象叫做cache颠簸(cache thrashing)。针对这个问题,引入多路组相连缓存。下面一节将讲解多路组相连缓存的工作原理。
多路组相连缓存多路组相连缓存的原理相比于直接映射缓存复杂一些,这里将以两路组相连这种场景来进行讲解。
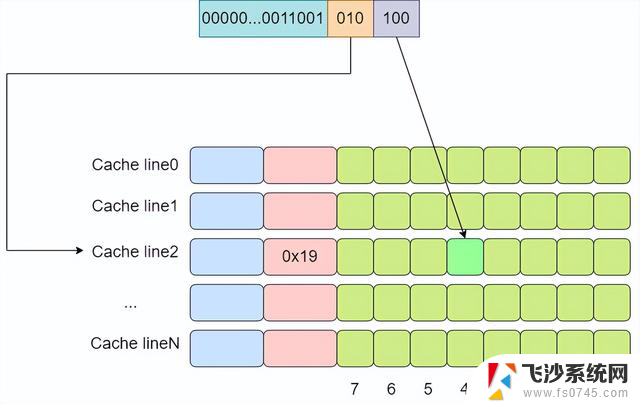
所谓多路就是指原来根据虚拟的地址中的index可以唯一确定一个cache line,而现在根据index可以找到多行cache line。而两路的意思就是指通过index可以找到2个cache line。在找到这个两个cache line后,遍历这两个cache line,比较其中的tag值,如果相等则代表命中了。
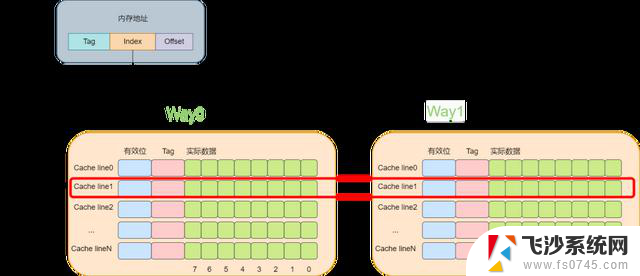
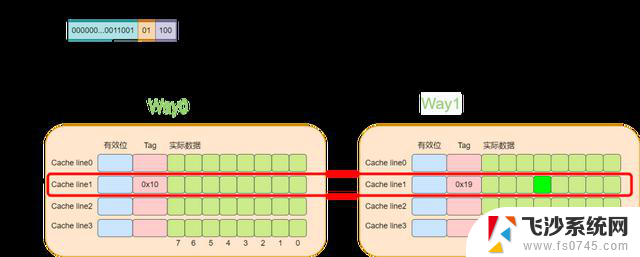
下面还是以8个cache line的两路缓存为例,假设现在有一个虚拟地址是0000001100101100,其tag值为0x19,其index为1,offset为4。那么根据index为1可以找到两个cache line,由于第一个cache line的tag为0x10,因此没有命中,而第二个cache line的tag为0x19,值相等,于是cache命中。
对于多路组相连缓存而言,其内存和缓存的映射关系如下所示:
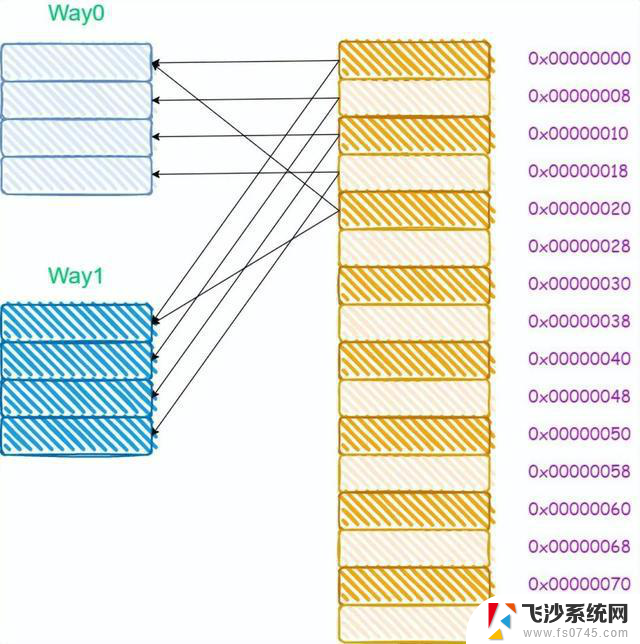
由于多路组相连的缓存需要进行多次tag的比较,对于比直接映射缓存,其硬件成本更高,因为为了提高效率,可能会需要进行并行比较,这就需要更复杂的硬件设计。
另外,如何cache没有命中,那么该如何处理呢?
以两路为例,通过index可以找到两个cache line,如果此时这两个cache line都是处于空闲状态,那么cache miss时可以选择其中一个cache line加载数据。如果两个cache line有一个处于空闲状态,可以选择空闲状态的cache line 加载数据。如果两个cache line都是有效的,那么则需要一定的淘汰算法,例如PLRU/NRU/fifo/round-robin等等。
这个时候如果我们依次访问了0x00,0x40,0x00会发生什么?
当我们访问0x00时,cache miss,于是从内存中加载到第0路的第0行cache line中。当访问0x40时,第0路第0行cache line中的tag与地址中的tag成分不一致,于是从内存中加载数据到第1路第0行cache line中。最后再次访问0x00时,此时会访问到第0路第0行的cache line中,因此cache就生效了。由此可以看出,由于多路组相连的缓存可以改善cache颠簸的问题。
全相连缓存从多路组相连,我们了解到其可以降低cache颠簸的问题,并且路数量越多,降低cache颠簸的效果就越好。那么是不是可以这样设想,如果路数无限大,大到所有的cache line都在一个组内,是不是效果就最好?基于这样的思想,全相连缓存相应而生。
下面还是以8个cache line的全相连缓存为例,假设现在有一个虚拟地址是0000001100101100,其tag值为0x19,offset为4。依次遍历,直到遍历到第4行cache line时,tag匹配上。
全连接缓存中所有的cache line都位于一个组(set)内,因此地址中将不会划出一部分作为index。在判断cache line是否命中时,需要遍历所有的cache line,将其与虚拟地址中的tag成分进行对比,如果相等,则意味着匹配上了。因此对于全连接缓存而言,任意地址的数据可以缓存在任意的cache line中,这可以避免缓存的颠簸,但是与此同时,硬件上的成本也是最高。
如何利用缓存写出高效率的代码?看下面这个例子,对一个二维数组求和时,可以进行按行遍历和按列遍历,那么哪一种速度会比较快呢?
标准输出打印了:8ms
答案很明显了,按行遍历速度比按列遍历快很多。
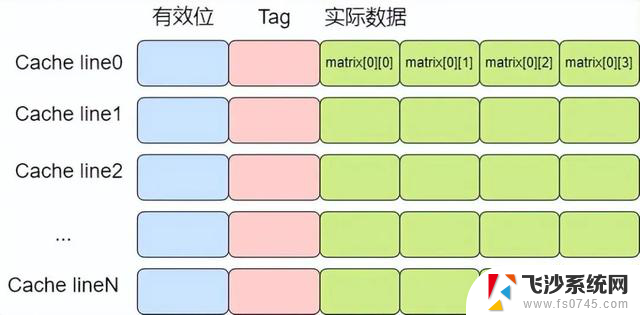
原因就是按行遍历时, 在访问matrix[r][c]时。会将后面的一些元素一并加载到cache line中,那么后面访问matrix[r][c+1]和matrix[r][c+2]时就可以命中缓存,这样就可以极大的提高缓存访问的速度。
如下图所示,在访问matrix[0][0]时,matrix[0][1],matrix[0][2],matrix[0][2]也被加载进了高速缓存中,因此随后遍历时就可以用到缓存。
而按列遍历时,访问完matrix[0][0]之后,下一个要访问的数据是matrix[1][0],不在高速缓存中,于是需要再次访问内存,这就使得程序的访问速度相较于按行缓存会慢很多。
带你认识CPU缓存:了解CPU缓存的工作原理和作用相关教程
-
 计算机的构造和原理之CPU介绍:深入了解中央处理器的工作原理
计算机的构造和原理之CPU介绍:深入了解中央处理器的工作原理2023-12-19
-
 服务器内部大揭秘(CPU、内存、硬盘):揭秘服务器内部工作原理和性能优化技巧
服务器内部大揭秘(CPU、内存、硬盘):揭秘服务器内部工作原理和性能优化技巧2024-02-23
-
 微软DirectX 12工作图发布:让GPU自主工作,突破CPU瓶颈,加速游戏性能
微软DirectX 12工作图发布:让GPU自主工作,突破CPU瓶颈,加速游戏性能2024-03-13
-
 CPU的使用寿命大概有多少年?解密CPU的寿命与使用年限
CPU的使用寿命大概有多少年?解密CPU的寿命与使用年限2024-01-04
- 十大提升Windows生产力技巧:让你的工作效率翻倍提升
- 经常玩游戏的你,认识显卡吗?了解显卡对游戏性能的重要性
- 台式机CPU怎样才算真性价比”?对比测试告诉你答案 - 最全面的台式机CPU性价比对比测试
- 英伟达和AMD旗舰显卡介绍,小白放心抄作业,让你轻松了解显卡选择技巧
- CPU对决GPU:深度学习背后的性能之王——哪个更适合你?
- 11月CPU推荐红黑榜,看看有没有合适你的一款。最新推荐
- 如何查看显卡型号和性能参数的详细步骤?快速了解显卡配置和性能指标
- NVIDIA RTX 5090新一代旗舰卡大曝光:接口、功耗巨变 售价猛涨
- 微软新专利展示折叠屏Surface Phone正面形态
- AMD AI9 365处理器掌机全新登场,性能强劲,售价仅需7699元
- 微软总裁:“中国正在科技领域赶上西方”:科技领域中国崛起的趋势如何助力实现领先地位?
- 极摩客EVO-X1迷你主机上新:HX 370处理器,定价5299元,性价比超高!
系统资讯推荐
- 1 如何查看显卡型号和性能参数的详细步骤?快速了解显卡配置和性能指标
- 2 AMD AI9 365处理器掌机全新登场,性能强劲,售价仅需7699元
- 3 微软总裁:“中国正在科技领域赶上西方”:科技领域中国崛起的趋势如何助力实现领先地位?
- 4 极摩客EVO-X1迷你主机上新:HX 370处理器,定价5299元,性价比超高!
- 5 AMD全球裁员上千人,市场“吓坏”!英伟达能否赶上?
- 6 Windows 11今起可以直接运行安卓APP了,微软操作系统迎来重大更新
- 7 涉及1000名员工!AMD宣布全球裁员4%,中国区也受影响,员工如何应对?
- 8 英伟达RTX 50系列显卡蓄势待发,40系列步入清仓阶段2022最新
- 9 摩尔线程启动IPO上市辅导,中国英伟达估值255亿!
- 10 AMD良心! ZEN6锐龙不换接口,性能强大,不用担心接口兼容问题
win10系统推荐
系统教程推荐
- 1 windowslink工作区 怎么关闭 如何在Windows10系统中启用Windows lnk工作区
- 2 输入法怎么拼音标声调 搜狗输入法拼音声调输入方法
- 3 打印机打印出来绿色 打印机打印绿色偏暗怎么调
- 4 手机如何开锁 如何解锁手机屏幕锁
- 5 怎么识别有没有摄像头 怎么判断设备有没有摄像头
- 6 路由器跟电脑怎么连接 路由器连接电脑的方法
- 7 win11自带杀毒可以用吗 win11需要安装杀毒软件吗
- 8 win11怎么显示后缀格式的文件 Win11文件类型后缀名显示方法
- 9 还原被win10删掉的软件 如何找回已删除的软件
- 10 windows10隐藏任务栏 怎样在Win10中隐藏任务栏