EfficientMod:微软出品,高效调制主干网络 | ICLR 2024- 提升深度学习效率的最佳选择
Efficient Modulation (EfficientMod) 融合了卷积和注意力机制的有利特性,同时提取空间上下文并对输入特征进行投影,然后使用简单的逐元素乘法将其融合在一起。EfficientMod的设计保证了高效性,而固有的调制设计理念则保证了其强大的表示能力来源:晓飞的算法工程笔记 公众号
论文: Efficient Modulation for Vision Networks
 论文地址:https://arxiv.org/abs/2403.19963论文代码:https://github.com/ma-xu/EfficientModIntroduction
论文地址:https://arxiv.org/abs/2403.19963论文代码:https://github.com/ma-xu/EfficientModIntroduction视觉Transformer(ViT)在广泛的视觉任务中展现了令人印象深刻的成就,并为视觉网络设计贡献了创新的思路。得益于自注意力机制,ViTs在动态特性和长距离上下文建模的能力上与传统卷积网络有所区别。然而,由于自注意力机制在视觉标记数量上具有二次复杂度,其既不具备参数效率也不具备计算效率,这阻碍了ViTs在边缘设备、移动设备和其他实时应用场景上的部署。因此,一些研究尝试在局部区域内使用自注意力,或者选择性地计算信息标记,以减少计算量。同时,一些工作尝试将卷积和自注意力结合起来,以实现理想的效果和效率的折衷。
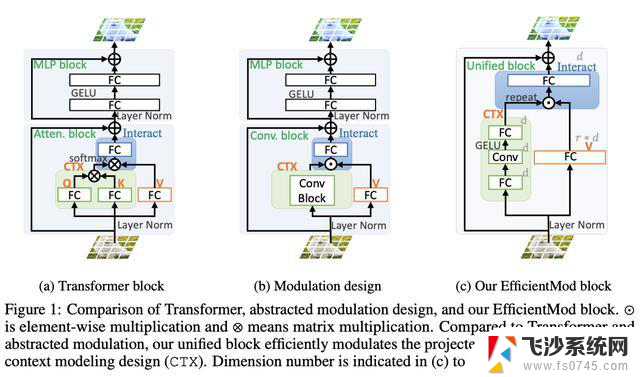
最近的一些研究表明,纯卷积网络也能够与自注意力相比取得令人满意的结果。其中,FocalNet和VAN以计算效率高和易于实现而著称,展现了领先的性能且显著优于ViT的对应模型。一般来说,这两种方法都使用大核卷积块进行上下文建模,并通过逐元素乘法调节投影输入特征(随后是一个MLP块),如图1b所示。这种设计统称为调制机制,它表现出有前景的性能,并且从卷积的有效性和自注意力的动态性中获益。尽管调制机制在理论上是高效的(从参数和FLOPs的角度来看),但在计算资源有限时推断速度不尽如人意。造成这种情况的原因主要有两个:
冗余和等效操作,如连续的深度卷积和冗余的线性投影占据了大部分操作时间。上下文建模分支中的碎片化操作显著增加了延迟,并违反了ShuffleNetv2中的指导原则G3。为此,论文提出了高效调制(Efficient Modulation),可以作为高效模型的基本构建块(见图1c)。与FocalNet和VAN的调制块相比,高效调制块更加简单并继承了所有的优点(见图1b和图1c)。与Transformer块相比,高效调制块的计算复杂度与图像尺寸呈线性关系,强调大规模但局部的特征交互,而Transformer则与标记数量的立方相关并直接计算全局交互。与反向残差(MBConv)块相比,高效调制块使用更少的通道进行深度卷积,并融入了动态特性。

基于高效调制(Efficient Modulation)块,论文提出了基于纯卷积的新型高效网络架构EfficientMod。EfficientMod块与传统的自注意力块正交,并且与其他设计具有良好的兼容性。通过将注意力块与EfficientMod集成的混合架构,可以产生更好的结果。在不使用神经网络搜索(NAS)的情况下,EfficientMod在各种任务中展现出非常不错的性能。与最先进方法EfficientFormerV2相比,EfficientMod-s在GPU上的速度比EfficientFormerV2-S2快25%,并且在top-1准确率上超过了EfficientFormerV2-S2约0.3个百分点。此外,EfficienntMod在下游任务中也显著超越了EfficientFormerV2,在ADE20K语义分割基准测试中,其mIoU比EfficientFormerV2高出了3.6个百分点,而模型复杂度相当。
MethodRevisit Modulation DesignVisual Attention NetworksVAN提出了一个简单且有效的卷积注意力设计。具体而言,给定输入特征,首先使用一个全连接(FC)层(带有激活函数)将投影到一个新的特征空间,然后将其输入到两个分支。第一个分支提取上下文信息,第二个分支是一个恒等映射。使用逐元素乘法来融合来自两个分支的特征,随后添加一个新的线性投影。具体来说,VAN块可以写成:
其中, 表示逐元素相乘, 表示具有核大小和扩张率的深度可分离卷积, 是上下文分支中的另一个全连接(FC)层。遵循MetaFormer的设计理念,VAN块被用作标记混合器,并且后续连接一个具有深度可分离卷积的双层MLP块作为通道混合器。
FocalNetsFocalNets引入了焦点调制来替代自注意力,同时享有动态性和较大的感受野。FocalNet还提出了一种并行的双分支设计,一个上下文建模分支自适应地聚合不同层次的上下文,一个线性投影分支将投影到一个新的空间。类似地,这两个分支通过逐元素相乘进行融合,然后使用一个FC层。形式上,FocalNet中的分层调制设计可以表示为(为了清晰起见,忽略全局平均池化层):
其中, 包括由具有大小为的深度可分离卷积层分层提取的层上下文信息, 将通道特征投影到一个门控值。 是在每个卷积层之后的GELU激活函数。
Abstracted Modulation MechanismVAN和FocalNet均展示出了良好的表征能力,并表现出令人满意的性能。实际上,这两种方法都共享一些不可或缺的设计,可能就是性能提升的关键:
这两个并行分支是独立操作的,从不同的特征空间提取特征,类似于自注意力机制(如图1a所示)。在上下文建模方面,两者均考虑了较大的感受野。VAN堆叠了两个具有扩张的大核卷积,而FocalNet引入了分层上下文聚合以及全局平均池化来实现全局交互。这两种方法通过逐元素相乘将来自两个分支的特征融合在一起,这在计算上是高效的。在特征融合之后采用了线性投影。与此同时,它们也存在着明显的不同设计,比如上下文建模的具体实现以及特征投影分支的设计(共享或独立投影)。基于上述相似之处并忽略特定的差异,论文将调制机制进行抽象,如图1b所示,并形式定义如下:
这个抽象的调制机制在理论上继承了卷积和自注意力的优良特性,但实际以卷积方式运算,且具有令人满意的效率。具体地,公式4由于逐元素相乘而具有类似自注意力的动态性。上下文分支还引入了局部特征建模,但也通过大的核大小实现了较大的感受野(这对效率来说不是瓶颈)。遵循VAN和FocalNet,在调制后引入一个两层MLP块。
Efficient Modulation尽管比自注意力更高效,但抽象的调制机制在理论复杂度和推理延迟方面仍无法满足移动网络的效率要求。因此,论文提出了高效调制(Efficient Modulation),旨在为高效网络量身定制的同时保留调制机制的所有优良特性。
Sliming Modulation Design通用的调制块具有许多零散的操作,如图1b所示。比如未考虑上下文建模实现的细节,引入了四个全连接(FC)层。正如ShuffleNetv2中的指导原则G3所述,即使通过调整通道数量可以降低计算复杂度,但太多的零散操作也将显著降低速度。因此,论文融合了MLP和调制块的FC层,如图1c所示。使用基于通过扩展因子来扩展通道维度,并利用来压缩通道数量。换句话说,MLP块与调制设计融合并且具有灵活的扩展因子,产生类似于MBConv块的统一块。
Simplifying Context Modeling为了提高效率,对上下文建模分支进行定制。给定输入,首先通过线性投影将投影到一个新的特征空间,然后使用具有GELU激活的深度可分离卷积来建模局部空间信息(设置核大小为7,作为平衡效率和较大感受野之间的折衷),最后使用线性投影进行通道间的信息交流。值得注意的是,在整个上下文建模分支中,通道数量保持不变。简而言之,上下文建模分支可以表示为:
这种设计比VAN和FocalNet中的上下文建模要简单得多,通过一个大核的深度可分离卷积抛弃了等效的多个深度可分离卷积。这可能会在一定程度上牺牲性能以换取效率,但消融研究表明,上下文分支中的每个操作都是必不可少的。
Network Architecture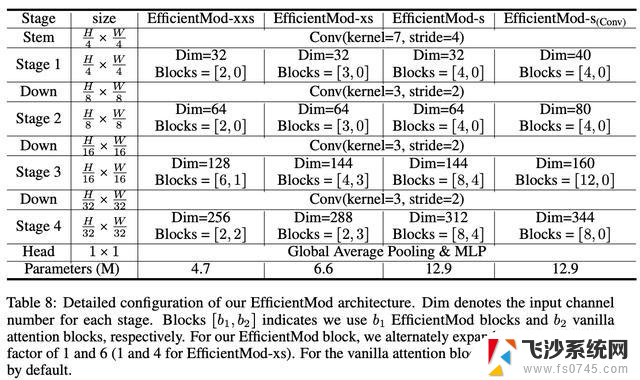
EfficientMod采用了4个阶段的分层架构,每个阶段由一系列带有残差连接的EfficientMod模块组成。为了简化起见,使用重叠的图像块嵌入(通过卷积层实现下采样)分别将特征减小4倍、2倍、2倍和2倍。对于每个模块,使用层归一化来对输入特征进行归一化,然后将归一化的特征输入EfficientMod模块。采用随机深度和层缩放来改善模型的鲁棒性。
需要注意的是,EfficientMod模块与自注意机制是正交的,将EfficientMod模块与注意力模块相结合即可得到一种新的混合设计。混合结构将原始注意力模块引入到特征尺寸相对较小的最后两个阶段,根据纯卷积型EfficientMod对应模块的参数进行宽度和深度修改,保证进行公平比较。一共设计三个规模的混合结构,参数范从4M到13M,分别为EfficientMod-xxs,EfficientMod-xs和EfficientMod-s。
Computational Complexity analysis给定输入特征,EfficientMod模块的总参数数量为,计算复杂度为,其中为卷积核大小,为中的扩张比率。为了简化,忽略了可学习层中的激活函数和偏置项。与注意力机制相比,EfficientMod模块的复杂度与输入分辨率呈线性关系。与MBConv相比,EfficientMod模块将深度可分离卷积的复杂度减少了倍(MBConv有升维操作),这对于有效性至关重要。
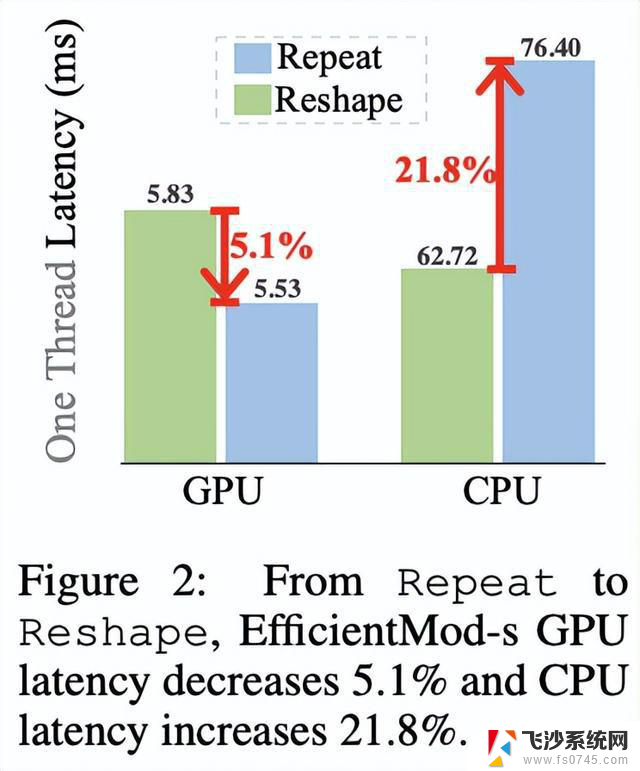
除了理论计算复杂度外,论文提供了一些实际指南:
通过将更多参数移至特征分辨率较小的后期阶段来减少FLOPs。这样做的原因在于EfficientMod的FLOPs基本上等于输入分辨率乘以参数数量。遵循这一指导方针,可以在后期阶段添加更多的模块或者大幅增加宽度。需要注意的是,这一指南并不仅适用于我们的EfficientMod,也可以应用于所有的全连接和卷积层。只在最后两个阶段引入注意力模块,考虑到自注意力的计算复杂度,这是许多研究中的一种常见做法。使用Repeat操作来匹配通道数(两个分支的输出特征),以节省CPU时间并仅需少量GPU开销。EfficientFormer观察到,对于许多模型来说,Reshape操作通常是瓶颈。Reshape在CPU上运行缓慢,但在GPU上友好。与此同时,Repeat操作在CPU上运行迅速,但在GPU上耗时。如图2所示(这里应该是图标反了),选择Repeat操作来获得最佳的GPU-CPU延迟折衷。(这一点有点疑问,这里使用Repeat是为了匹配少了的维度数,Reshape应该达不到这个效果。私信了作者,这里的Reshape实际为torch.broadcast_to函数)Relation to Other ModelsMobileNetV2通过引入Mobile Inverted Bottleneck(简称MBConv)模块,MobileNetV2开启了高效网络领域的新时代。与顺序排列全连接层的MBConv模块相比,EfficientMod模块将深度可分离卷积层分离出来,并通过逐元素乘法将其插入到两层全连接网络的中间。由于深度可分离卷积的通道数量减少,EfficientMod是一种更高效的操作,并且在性能上取得了更好的表现(由于调制操作)。
SENetSENet通过提出通道注意力机制向ConvNets引入了动态特性,SE块可以表示为。最近许多研究将其纳入,从而在理论上保持低复杂度的同时实现更好的准确性。然而,由于SE块中的零碎操作多,实际会显著降低GPU上的推理延迟。相反,EfficientMod模块通过连贯地进行通道注意力,其中自适应地调整了的通道权重。
Experiments对EfficientMod在四个任务上进行验证:在ImageNet-1K上进行图像分类, 在MS COCO上进行目标检测和实例分割,在ADE20K上进行语义分割。在PyTorch中实现了所有网络,并将其转换为ONNX模型在两种不同的硬件上进行测试:
GPU:选择P100 GPU进行延迟评估,因为它可以模拟近年来大多数设备的计算能力。其他GPU可能会产生不同的基准结果,但我们观察到趋势是类似的。CPU:一些模型在不同类型的硬件上可能会产生不可预测的延迟(主要是由内存访问和零碎操作引起的),在Intel(R) Xeon(R) CPU E5-2680上的所有模型的测得延迟以进行全面比较。对于延迟基准测试,将批处理大小分别设置为1,以模拟真实世界的应用。为了抵消方差,对每个模型重复进行4000次运行,并报告平均推理时间。遵循常见的做法,使用四个线程同时测试。
Image Classification on ImageNet-1K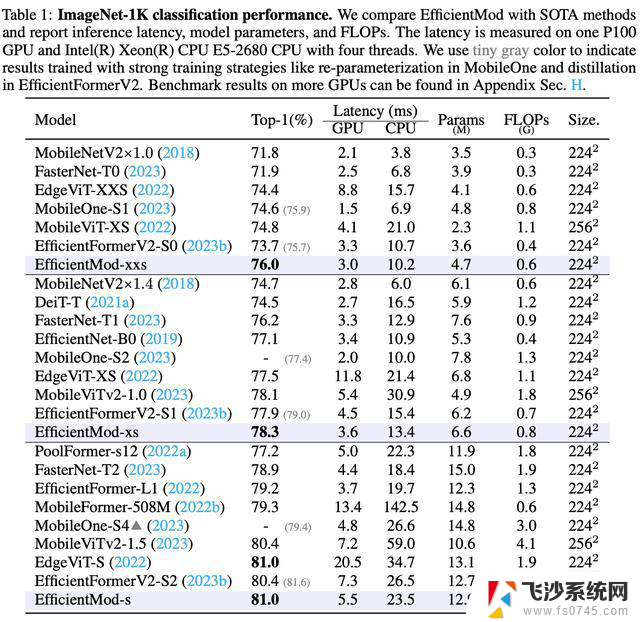
EfficientMod在不同硬件上的分类精度和推理延迟方面表现出色。例如,EfficientMod-s在GPU上比EdgeViT表现相同,但运行速度快了15毫秒(约快73%),在CPU上快了11毫秒(约快32%)。此外,参数和计算复杂度也更少。EfficientMod-s在GPU上也比EfficientFormerV2-S2有0.6提升,运行速度快了1.8毫秒(约快25%)。需要注意的是,一些高效设计(例如MobileNetV2和FasterNet)注重低延迟。而其他模型则注重性能(例如MobileViTv2和EdgeViT),而EfficientMod在GPU和CPU上运行速度快且提供了最先进的性能。
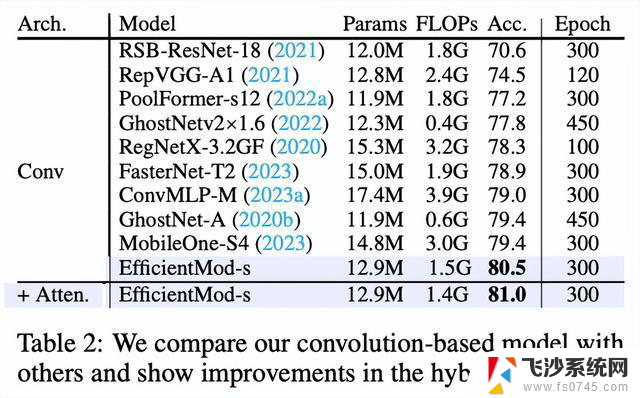
为了更好地了解EfficientMod的改进,我们以EfficientMod-s为例,概述了每个修改的具体改进。从纯卷积基础版本到混合模型,都显示在了表2中。即使EfficientMod的纯卷积基础版本已经以80.5%的显著结果,明显超过相关的基于卷积的网络。通过调整为混合架构,还可以进一步将性能提升至81.0%。
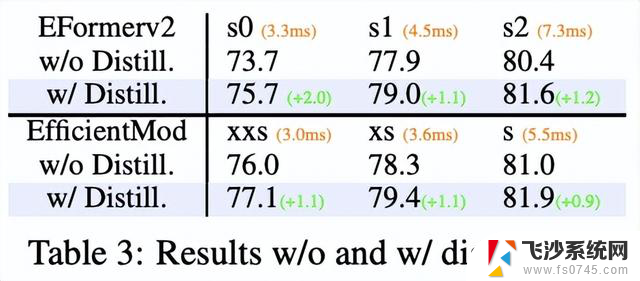
同时,一些方法采用了强大的训练策略,比如MobileOne中的重新参数化和EfficientFormerV2中的蒸馏。经过蒸馏训练,可以将EfficientMod-s的精度从81.0%提升到81.9%,如表3所示。
Ablation StudiesCompare to other Modulation models
将EfficientMod-xxs与具有相似参数数量的FocalNet和VAN-B0进行比较。为了公平比较,通过减少通道或块数量的方式定制了FocalNet_Tiny_lrf。一共测试了三种变体,选择了性能最好的一个并将其称为FocalNet@4M。由于Conv2Former的代码尚未完全发布,在比较中没有考虑它。从表4可以看出,EfficientMod在精度和延迟方面均优于其他调制方法。
Ablation of each component
在没有引入注意力和知识蒸馏的卷积EfficientMod-s上进行实验,检验每个组件所带来的贡献。表5显示了在上下文建模分支中消除每个组件的结果。显然,所有这些组件对最终的结果至关重要,引入所有组件后获得了80.5%的top-1准确率。同时,还进行了一个实验来验证逐元素相乘的有效性,用求和来替代(相同的计算和相同的延迟)融合两个分支的特征。如预期一样,准确率下降了1%。显著的性能下降揭示了调制操作的有效性,特别是在高效网络中。
Connection to MBConv blocks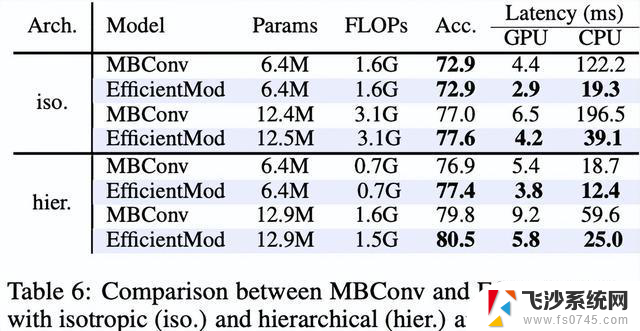
为了验证EfficientMod块的优越性,与具有各向同性和分层结构的基础MBConv进行了比较。在几乎相同数量的参数和FLOPs的情况下,表6中的结果表明,EfficientMod在GPU和CPU上均比MBConv快得多。最有可能的解释EfficientMod的深度可分离卷积比MBConv的要轻得多(分别是和的通道数,其中设置为6)。除了更快的推理速度,EfficientMod始终比MBConv块提供了更优越的实证结果。
Context Visualization
继承自调制机制,EfficientMod块能够区分有信息量的上下文。在与FocalNet相似的基础上,在EfficientMod-Conv-s中可视化了上下文层的推理输出(沿通道维度计算均值),如图4所示。显然,EfficientMod始终捕捉到有信息量的对象,而背景受到了约束,这表明了调制机制在高效网络中的有效性。
Object Detection and Instance Segmentation on MS COCO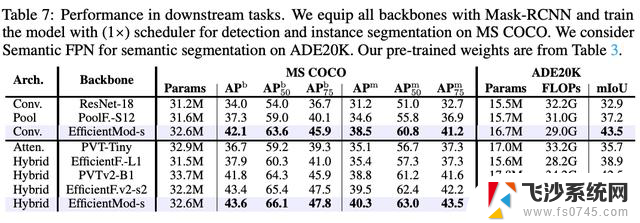
为验证EfficientMod在下游任务中的性能,在MS COCO数据集上进行了目标检测和实例分割的实验。将EfficientMod-s应用到常用的Mask RCNN检测器上进行验证。遵循以往研究的实现,使用调度器,即12个epochs来训练模型。将卷积型和混合型EfficientMod-s与其他方法进行比较。如表7所示,EfficientMod始终优于具有相似参数的其他方法。在没有自注意力的情况下,EfficientMod在检测任务上比PoolFormer高出4.2个mAP,在实例分割任务上高出3.6个mAP。当引入注意力并与混合模型进行比较时,EfficientMod在两个任务上仍然优于其他方法。
Semantic Segmentation on ADE20K在ADE20K数据集上进行语义分割任务的实验。考虑简单高效的设计,选择Semantic FPN作为分割模型。遵循之前的研究,在8个A100 GPU上进行了40,000次迭代训练,数据批次为32。使用AdamW优化器对模型进行训练,使用余弦退火调度器从初始值2e-4衰减学习率。
表7中的结果表明,EfficientMod在性能上明显优于其他方法。在没有使用注意力的情况下,卷积型EfficientMod-s的mIoU已经比PoolFormer高出6.3个百分点。此外,纯卷积型EfficientMod甚至获得了比使用注意力方法更好的结果。在这方面,卷积型EfficientMod-s的性能比之前的SOTA高效方法EfficientFormerV2提升了1.1个mIoU。当引入Transformer块以获得混合设计时,使用相同数量的参数甚至更少的FLOPs也能将性能进一步提升至46.0的mIoU。混合型EfficientMod-s的性能显著优于其他混合网络,分别比PvTv2和EfficientFormerV2高出3.5和3.6个mIoU。可以得出两个结论:
EfficientMod的设计取得了重大进步,证明了其价值和有效性。大的感知域对于分割等高分辨率输入任务尤为有益,而基本的注意力块(实现全局范围)可以成为高效网络的现成模块。如果本文对你有帮助,麻烦点个赞或在看呗~undefined更多内容请关注 微信公众号【晓飞的算法工程笔记】
work-life balance.
EfficientMod:微软出品,高效调制主干网络 | ICLR 2024- 提升深度学习效率的最佳选择相关教程
-
-
 微软将为Win11记事本带来“Cowriter”AI功能——提升您的写作效率
微软将为Win11记事本带来“Cowriter”AI功能——提升您的写作效率2024-01-10
-
-
 微软4月更新邀请更多Win11用户体验Copilot,提升编程效率
微软4月更新邀请更多Win11用户体验Copilot,提升编程效率2024-04-13
- 微软Copilot和Telegram聊天机器人上线,助力开发者提升效率
- 十大提升Windows生产力技巧:让你的工作效率翻倍提升
- CPU对决GPU:深度学习背后的性能之王——哪个更适合你?
- 微软Copilot“大脑”将升至GPT-4 Turbo,并提高字符上限,让您的编程体验更加智能高效
- 微软Windows 11迎来重大升级,AI助手Copilot现已加入,助你提升工作效率
- 为专业人士提高生产力,AMD Ryzen AI生态进一步扩展:助力专业人士提升工作效率
- 如何查看显卡型号和性能参数的详细步骤?快速了解显卡配置和性能指标
- NVIDIA RTX 5090新一代旗舰卡大曝光:接口、功耗巨变 售价猛涨
- 微软新专利展示折叠屏Surface Phone正面形态
- AMD AI9 365处理器掌机全新登场,性能强劲,售价仅需7699元
- 微软总裁:“中国正在科技领域赶上西方”:科技领域中国崛起的趋势如何助力实现领先地位?
- 极摩客EVO-X1迷你主机上新:HX 370处理器,定价5299元,性价比超高!
系统资讯推荐
- 1 如何查看显卡型号和性能参数的详细步骤?快速了解显卡配置和性能指标
- 2 AMD AI9 365处理器掌机全新登场,性能强劲,售价仅需7699元
- 3 微软总裁:“中国正在科技领域赶上西方”:科技领域中国崛起的趋势如何助力实现领先地位?
- 4 极摩客EVO-X1迷你主机上新:HX 370处理器,定价5299元,性价比超高!
- 5 AMD全球裁员上千人,市场“吓坏”!英伟达能否赶上?
- 6 Windows 11今起可以直接运行安卓APP了,微软操作系统迎来重大更新
- 7 涉及1000名员工!AMD宣布全球裁员4%,中国区也受影响,员工如何应对?
- 8 英伟达RTX 50系列显卡蓄势待发,40系列步入清仓阶段2022最新
- 9 摩尔线程启动IPO上市辅导,中国英伟达估值255亿!
- 10 AMD良心! ZEN6锐龙不换接口,性能强大,不用担心接口兼容问题
win10系统推荐
系统教程推荐
- 1 win11如何投屏到电视机上 海信电视投屏设置步骤
- 2 win11笔记本颜色怎么调 电脑屏幕颜色调节方法
- 3 win11ait+tab不能切换 win11 alt tab切换不了窗口的解决方法
- 4 win11任务栏图标大小修改 win11任务栏图标大小调整方法
- 5 电脑win10动态壁纸 win10电脑动态壁纸设置步骤
- 6 win11文件夹右键更多选项 Win11右键菜单显示更多选项怎么设置
- 7 win11电脑自带的画图在哪里 Win11画图工具打开方法
- 8 win11可以开热点么 笔记本电脑如何创建热点
- 9 win11便签 华为手机 秒记记事桌面便签设置方法
- 10 win 10电脑连不上网络怎么办 笔记本连接不上无线网络怎么办