处理器“三国鼎立”:从CPU、GPU到DPU,解析处理器类型及应用领域
背景

当2020年10月份,NVIDIA在其GTC 2020大会上大张旗鼓的宣传DPU之后,整个行业热了起来,大家都在问:什么是DPU?DPU到底能干什么?DPU和GPU有什么区别?号称数据中心三大处理器之一的DPU,“何德何能”与CPU、GPU并驾齐驱?
本文站在体系结构的视角,从技术演进的角度,讲一讲从CPU、GPU到DPU的演进,以及三者之间的协作关系。期望能够解答大家的疑惑。
1 从冯·诺依曼架构说起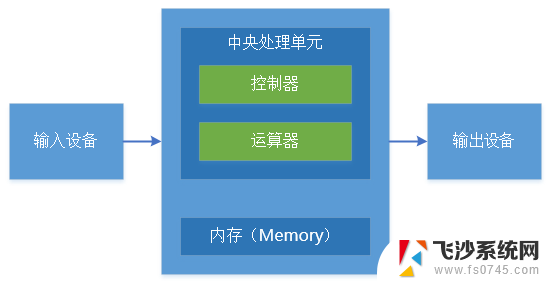
冯·诺依曼架构模型是计算机系统的经典模型,简单说,就是一个计算机系统包括输入、处理和输出三个部分。处理部分有控制单元、计算单元和数据暂存,处理部分的控制单元和计算单元组成大家通常理解的中央处理单元CPU。这样,内存作为CPU的输入和输出,CPU内部的寄存器则作为暂存。
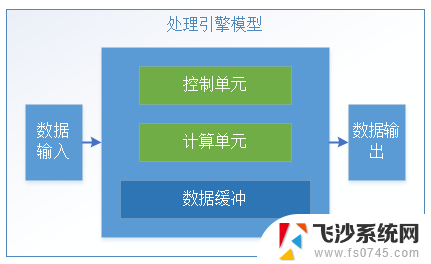
如图所示,不仅仅是CPU,其他各种处理引擎本质上都是基于冯·诺依曼架构的。我们把经典的冯·诺依曼架构进一步抽象化,即变换成一个通用的系统处理模型。整个模型包括:
数据的输入输出。主要负责跟外部的数据交互;控制单元:主要负责接收控制命令并且执行对整个处理引擎的控制和状态反馈;计算单元:主要负责具体数据的处理;数据缓冲:负责计算过程中临时数据的存储。而CPU和其他处理引擎最大不同在于:CPU是Self-Control,也就是说CPU是图灵完备的;而其他处理引擎需要有外部的系统来控制处理引擎的运行,也即是说这些处理引擎通常是不图灵完备的。
虽然现在大家讲非冯架构,但本质上,各种创新的计算架构都是基于同样的(冯·诺依曼架构的)思想,可以看做:
要么是冯·诺依曼架构的变种;要么是多个冯·诺依曼架构的组合;要么是上述两者兼而有之。2 从软件到硬件,存在很多中间形态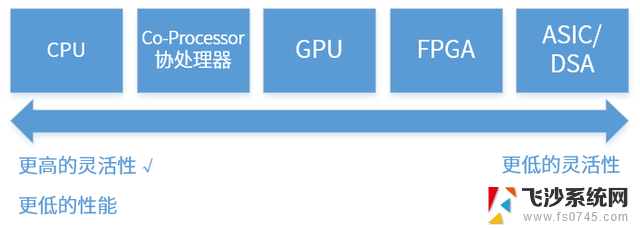
之前发布过一篇文章《什么是软件,什么是硬件》,在这篇文章中,我们讲解了软件和硬件的定义,以及为什么硬件可以加速等相关的一些基本技术原理。
在本篇文章中,我们不展开来讲。只强调一些基本的概念:
指令是软件和硬件交互的媒介,指令的复杂度决定了系统的软硬件解耦的程度;按照单位计算(指令)的复杂度,处理器平台典型的分为CPU、协处理器、GPU、FPGA、ASIC/DSA。从CPU到ASIC,单位计算越来越复杂,而灵活性却越来越低。任务在CPU运行,则定义为软件运行;任务在协处理器、GPU、FPGA或ASIC运行,则定义为硬件加速运行。参考阅读:什么是软件,什么是硬件。
3 CPU,划时代意义的发明3.1 指令集,软件和硬件的媒介CPU之前,传统计算机我们通常称为“固定程序计算机”(Fixed-Program Computer),由于它们的线路必须被重设才能执行不同的程序。而CPU解决了这一问题,CPU通过支持跳转、调用等控制类指令,可以很方便的把很多程序块动态的组织到一起,形成非常复杂并且功能强大的程序,或者称为软件。
很多人会认为,CPU可以自动的执行非常复杂的计算机程序,这是CPU最大的价值所在。其实不然,CPU最大的价值在于提供并规范了标准化的指令集,使得软件和硬件从此解耦:
硬件工程师不需要关心场景,只关注于通过各种“无所不用其极”的方式,快速的提升CPU的性能。而软件工程师,则完全不用考虑硬件的细节,只关注于程序本身。然后有了高级编程语言/编译器、操作系统以及各种系统框架/库的支持,构建起一个庞大的软件生态超级帝国。CPU是最灵活的,原因在于运行于CPU指令都是最基本的加减乘除外加一些访存及控制类指令,就像积木块一样,我们可以随意组合出我们想要的各种形态的功能。
不管是RISC还是CISC,说的是指令的复杂度。如今,即使是RISC,也需要在最简单的高频使用的指令集合的基础上,再增加一些复杂的指令集扩展。当前的CPU,除了常规的各种微架构设计层次的性能手段,从指令集的层次,都在不断的扩展更多复杂的指令集。站在软硬件定义的角度,现代的CPU,基本都包括了很多协处理器加速的成分。
3.2 软硬件解耦,CPU性能狂飙,软件蓬勃发展通过标准化指令集,达到软硬件解耦,并且互相向前兼容(软件向前兼容之前的硬件,硬件向前兼容之前的软件)。这样,CPU的硬件设计者,可以不用考虑上层的业务到底是什么,也即不关心通过指令组合出的程序到底是干什么用的。只需要关心,我设计的CPU性能如何的好,可以实现更高的IPC(Instructions per Cycle)和更高的频率。
提升CPU的性能手段,主要体现为如下方面:
时间并行度。通过流水线,在同一时刻有更多的指令进行处理。通过进一步的增加流水线级数,也即增加同一时刻处理的指令数量来提升性能。当然了,因为指令流本身的各种依赖,通过流水线的方式,会产生很多额外的代价,我们还需要通过分支预测、重命名、重排序缓冲ROB等机制来进一步减少流水线Stall的次数,来进一步优化时间并行。空间并行度。空间并行有很多维度,从指令级别的指令多发射、多执行单元,到超线程,到处理器多核等,都进一步的提升CPU的空间并行度。工艺进步,进一步提升设计规模和运行速度。使得单个CPU Core的很多复杂设计可以完成,并且使得可以在单芯片中集成更多的CPU Core,以此来进一步提升并行能力。存储Hierarchy。随着处理器性能的飞速提升,内存和处理器性能差距越来越大。因为程序局部性原理,为了进一步弥合两者的速率差距,在处理器和内存之间,增加了多级缓存。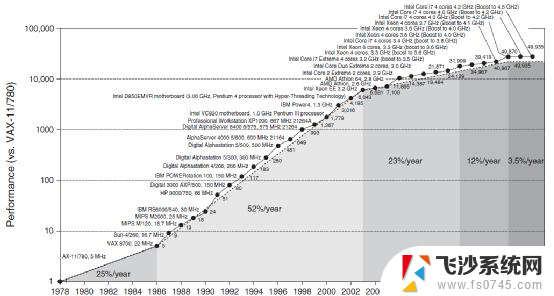
从图中,可以看到,在差不多40年的时间里,CPU的整体性能提升接近50000倍。一方面,这有赖于处理器架构的翻天覆地变化,也有赖于半导体工艺的进步。另一方面,更有赖于通过标准化的指令集,使得CPU平台的硬件实现和软件编程完全解耦,没有了对方的掣肘,软件和硬件均可以完全的放飞自我。
一方面是CPU性能狂飙,另一方面,则是软件逐渐发展成了一个超级的生态帝国。从各种数以百万级使用者的高级编程语言,到广泛使用在云计算数据中心、PC机、手机等终端的智能操作系统,再到各种专业的数据库、中间件,以及云计算基础的虚拟化、容器等。上述这些软件都是基础的支撑软件,是软件的“冰山一角”,而更多的则是各种用户级的应用软件,系统级和应用的软件,共同组成了基于CPU的软件超级生态。
3.3 CPU持续发展,达到性能瓶颈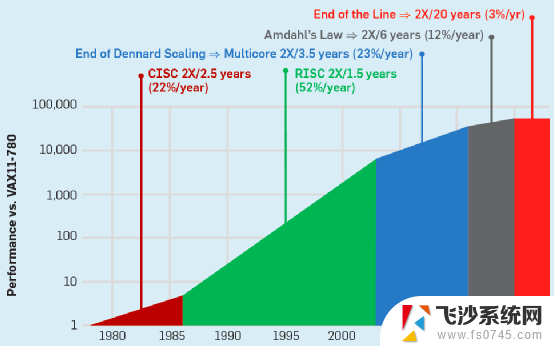
上图和上一节的图是一致的,上图主要是明确展示了五个发展阶段:
CISC阶段。在上世纪80年代,以Intel和AMD的x86架构为典型代表的CISC架构CPU开启了CPU性能快速提升的时代,CPU性能每年提升约25%(图中22%数据有误),大约3年性能可以翻倍。RISC阶段。随后,CISC系统越来越复杂,有很多设计资源花在了不经常使用的指令实现上。随后,RISC证明了“越精简,越高效”。随着RISC架构的CPU开始流行,性能提升进一步加快,每年可以达到52%,性能翻倍只需要18个月。多核阶段。单核CPU的性能提升越来越困难,开始通过集成更多CPU核并行的方式来进一步提升性能。这一时期,每年性能提升可以到23%,性能翻倍需要3.5年。多核整体性能递减阶段。随着CPU核集成的数量越来越多,阿姆达尔定律证明了处理器数量的增加带来的收益会逐渐递减。这一时期,CPU性能提升每年只有12%,性能翻倍需要6年。性能提升瓶颈阶段。不管是从架构/微架构设计、工艺、多核并行等各种手段都用尽的时候,CPU整体的性能提升达到了一个瓶颈。如图,从2015年之后,CPU性能每年提升只有3%,要想性能翻倍,需要20年。4 GPU,不仅仅是GPU4.1 GPGPU,通用的并行计算平台GPU,Graphics Processing Units,图形处理单元。顾名思义,GPU是主要用于做图形图形处理的专用加速器。GPU内部处理是由很多并行的计算单元支持,如果只是用来做图形图像处理,有点“暴殄天物”,其应用范围太过狭窄。
因此把GPU内部的计算单元进行通用化重新设计,GPU变成了GPGPU。到2012年,GPU已经发展成为高度并行的众核系统,GPGPU有强大的并行处理能力和可编程流水线,既可以处理图形数据,也可以处理非图形数据。特别是在面对SIMD类指令,数据处理的运算量远大于数据调度和传输的运算量时,GPGPU在性能上大大超越了传统的CPU应用程序。现在大家所称呼的GPU通常都指的是GPGPU。
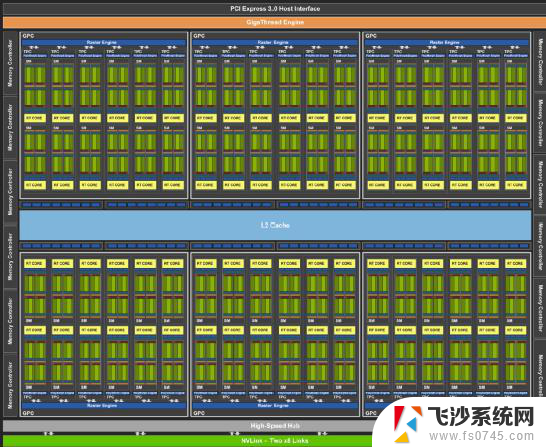
2018年,NVIDIA发布了最新一代的GPU架构——图灵架构。基于图灵架构的GPU提供PCIe 3.0来连接CPU主机接口,提供千兆的线程引擎来管理所有的工作。另外,图灵架构支持通过两路x8的NVLink接口实现多GPU之间的数据一致性访问。
如上图,图灵架构GPU的核心处理引擎由如下部分组成:6个图形处理簇(GPC);每个GPC有6个纹理处理簇(TPC),共计36个TPC;每个TPC有2个流式多核处理器(SM),总共72个SM。每个SM由64个CUDA核、8个Tensor核、1个RT核、4个纹理单元,总计有4608个CUDA核、576个Tensor核、72个RT核、288个纹理单元。
4.2 CUDA,NVIDIA GPU成功的关键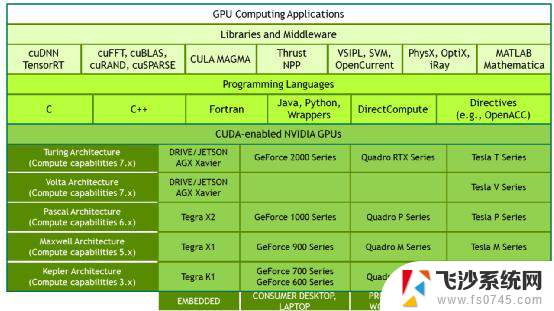
2006年NVIDIA推出了CUDA,这是一个通用的并行计算平台和编程模型,利用NVIDIA GPU中的并行计算引擎,以一种比CPU更高效的方式解决许多复杂的计算问题。CUDA提供了开发者使用C++作为高级编程语言的软件环境。也支持其他语言、应用程序编程接口或基于指令的方法,如FORTRAN、DirectCompute、OpenACC。
CUDA是NVIDIA成功的关键,它极大的降低了用户基于GPU并行编程的门槛,在此基础上,还针对不同场景构建了功能强大的开发库和中间件,逐步建立了GPU+CUDA的强大生态。
4.3 GPU,AI加速的王者
TensorFlow以及其他深度学习类的AI算法,非常依赖计算性能。通过密集的计算,训练所需的深度学习模型。计算越多,模型精度越高。当通用的多核CPU平台不足以支持深度学习所需要的计算量时,基于GPU加速的深度学习平台得到了广泛的应用。甚至Google开发了专用的TensorFlow处理器TPU来进一步加速AI算法的处理。
AI类算法通常有三类可能的计算平台:
基于CPU。CPU虽然灵活性很好,并且唾手可得,可以很好的做前期验证。但CPU标量计算,性能相对较弱,不能很好的满足AI类算法对性能的要求。基于(CPU+)ASIC/DSA。谷歌的TPU是非常经典的AI DSA案例,TPU是张量计算,性能非常好。但这里面临如下一些挑战:(1)芯片设计的门槛和周期;(2)ASIC/DSA与业务场景(或者说算法)的深度绑定;(3)是否可以大范围落地使用;(4)开发者的编程难度问题。这些问题,都使得ASIC/DSA非常难以芯片的方式交付给用户去做开发。例如,谷歌的TPU和AWS的Inferentia均是以服务的方式提供给客户使用。基于(CPU+)GPU。GPU的优势在于,其向量运算,一方面性能比CPU有很大提升,另一方面,可以通过CUDA支持用户编程。在CUDA的基础上,通过相关开发库及AI框架的支撑,使得开发者可以很方便的完成AI算法的开发、测试和部署。5 经典CPU+xPU异构计算的挑战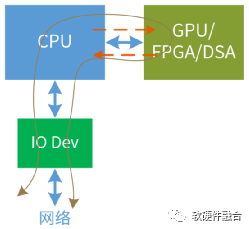
异构加速的实现架构通常是CPU+GPU/FPGA/DSA,主要由CPU完成不可加速部分的计算以及整个系统的控制调度。由GPU/FPGA完成特定任务的加速。这种架构面临一些挑战:
可加速部分占整个系统的比例有限,例如加速占比为80%,则加速最高不超过5倍;数据在CPU和加速器之间来回搬运的影响,加速比率打了折扣,有些场景综合加速效果不明显;异构加速显式的引入新的实体,计算变成两个或多个实体显式的协作完成,增加了整个系统的复杂度;虽然GPU相比CPU性能提升不少,但是相比DSA/ASIC的性能,还是有显著的差距;而DSA/ASIC的问题则在于,无法适应复杂场景对业务灵活性的要求,导致大规模应用成为巨大的门槛;CPU+xPU架构,是以CPU为中心,整个IO路径很长,IO成为性能的瓶颈。5.1 扩展:定制不是未来专用芯片指实现为某种DSA/ASIC架构的设计,DSA/ASIC相对的具有最高的性能同时最低的灵活性。这样的实现具有如下两类挑战:
不同的场景不同的算法。而DSA/ASIC架构跟算法紧密结合,只能覆盖少量的场景。上层的算法快速迭代,算法可能半年或一年就会有一次大的升级。而芯片的研发周期却需要2-3年,而其生命周期4-5年。在6-8年的周期里,DSA/ASIC很难满足算法如此频繁的迭代。芯片的一次性研发成本很高,只有大规模使用才能摊薄这些研发开销。而DSA/ASIC所面临的上述挑战,使得芯片的大规模落地成为难题。需要找到一个合适的设计方案,既能保证性能、又能保证灵活性,覆盖更多多久的场景,这样才能真正解决大规模复制的问题。
站在工程设计的角度,定制设计是一种紧耦合的设计,系统复杂度高,并且Case by Case,后续需要无止境的持续开发,代价很大。相对的,需要深入的分析业务场景,达到某种层次上的软硬件解耦(解耦降低系统复杂度),之后形成某种偏平台化的设计。软件和硬件各司其职,完成各自的工作;解耦之后再协同,达到最大限度的功能、性能、灵活性等多方面的均衡甚至兼顾。
6 DPU横空出世,面向未来6.1 CPU的算力瓶颈,量变引起质变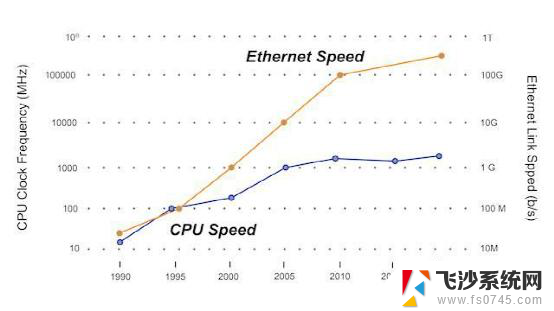
CPU(数据计算处理)和IO(数据输入输出)两者的此消彼长,决定了整个计算的架构:
第一阶段,“史前”阶段。在CPU之前的年代,CPU的处理速度和IO的输入输出速度基本匹配,因此也谈不上以谁为中心。IO部分负责数据的输入和输出,核心的计算模块负责具体的计算。第二阶段,CPU迅猛发展阶段。CPU发明后,通过标准的指令集,解耦了软件和硬件。CPU开始性能狂飙,而内存和外存的性能提升却非常有限。这时候,我们不得不设计非常多层级的存储hhierarchy来弥补IO(内存也可以当做CPU的数据IO)和CPU之间巨大的性能差距。这样,以CPU的计算为中心成为了整个计算机最核心的架构。第三阶段,CPU瓶颈+数据爆炸阶段。再进一步的,时间来到了大数据时代。网络带宽升级到百Gbps以上,存储更换成更高IOPS的NVMe SSD。可预见的未来,网络和存储的带宽还会持续的增加,暂时看不到停顿的迹象。而与此同时,CPU的性能却陷入了停滞。这样,以CPU计算为中心的架构越来越无法满足计算性能的要求,计算机架构未来会逐渐演化成以数据为中心的架构。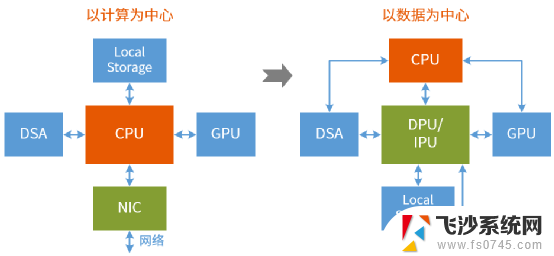
参考阅读:Fungible,以数据为中心时代来临。
6.2 面向超大规模数据处理的新一代异构计算架构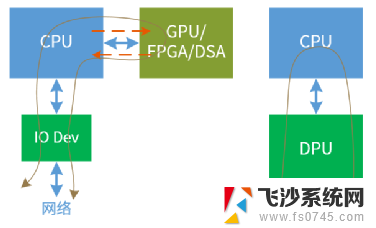
为什么我们说以数据为中心是新一代异构计算架构,跟传统的CPU+xPU架构有什么区别?具体见下表。
异构计算GPU/FPGA/DSA
以数据为中心DPU
IO路径
CPU+xPU架构IO路径太长,IO成为整个算力的瓶颈。
IO路径只从IO设备到CPU,甚至有些处理,完全不进CPU(快慢路径)。整个路径更短更高效。
输入输出损耗
CPU+xPU加速增加了额外的CPU和xPU之间的数据输入输出损耗。
DPU架构因为处于本来就存在的IO路径上,属于inline计算,因此,可以认为不存在额外的损耗。
系统复杂度
异构计算是显式的,CPU侧软件知道在做加速,CPU侧需要处理与加速器侧的数据和消息交互。
DPU采取的是offload机制,是两个系统之间的交互。DPU侧任务的控制面等复杂度屏蔽在DPU内部。
加速效果
GPU灵活性高加速效率低一些;DSA加速效率高一些,但灵活性低一些。
DPU是多异构混合架构,为上层CPU呈现极致的灵活性,而整体又是表现为极致的(DSA/ASIC级别的)性能。
与CPU的关系
CPU+xPU是CPU的辅助,需要CPU控制xPU的运行。
DPU是CPU和GPU/FPGA/DSA的支撑,通过设备/加速器/服务接口,服务于上层业务。
6.3 DPU的定位和主要的功能
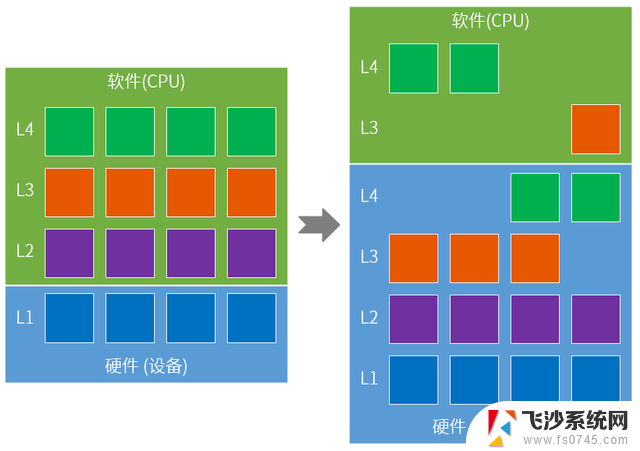
把服务器看做是一个系统,那么这个复杂的系统必然呈现出某种分层的架构;未来几年的云计算数据中心都具有更加庞大的规模。我们可以主要说,由于(1)复杂的分层的系统、(2)CPU的性能瓶颈、(3)宏观的超大规模以及(4)基于特定场景服务。使得整个系统要想持续不断的提升性能,就需要不断的把Workload从软件持续不断的卸载到硬件加速。
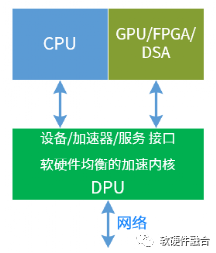
DPU定位为完成性能敏感的并且通用的工作任务加速处理,更好的支撑CPU、GPU的上层业务。DPU完成基础工作任务,构建强大的基础设施层,服务云计算上层业务的快速创新。

DPU对外的接口主要是PCIe和Ethernet。中间包括网络、存储、虚拟化、安全等各种加速任务的处理。扩展的:
DPU也可以集成一些应用层级的加速器,如AI-DSA加速、基于嵌入式GPU/FPGA的弹性加速等,进一步强大DPU的功能。DPU也可以集成高性能的嵌入式CPU,把一些跟DPU硬件加速任务关系紧密的软件Workload放在嵌入式CPU运行,进一步提升整体的效率。PS:DPU具有如此强大的功能,再叫DPU是不是已经不太准确了?嗯,是的,因此,我给起了个新的名字,IPU,Infrastructure Processing Unit,基础设施处理单元。
欢迎关注“软硬件融合”公众号:
长按扫描二维码加“软硬件融合”技术讨论群。
处理器“三国鼎立”:从CPU、GPU到DPU,解析处理器类型及应用领域相关教程
-

-
 锐龙处理器性能评测:值得购买吗?——全面解析AMD锐龙处理器性能,值不值得购买一目了然
锐龙处理器性能评测:值得购买吗?——全面解析AMD锐龙处理器性能,值不值得购买一目了然2024-10-29
-
 大裁员、股价大跌、处理器不稳定,英特尔怎么了?英特尔处理器不稳定原因分析
大裁员、股价大跌、处理器不稳定,英特尔怎么了?英特尔处理器不稳定原因分析2024-08-05
-
 目前前25处理器排名,看一下你手机处理器排第几?手机处理器排名查询
目前前25处理器排名,看一下你手机处理器排第几?手机处理器排名查询2024-10-20
- AMD锐龙9000系列处理器性能对比:中高端处理器横向竞争分析
- 6大国产CPU中,有2大已经胜出了?揭秘最强国产处理器!
- AMD Zen5处理器性能无敌?暴涨45%,性能超越Intel处理器
- AMD处理器安全漏洞曝光:已存在18年,数亿处理器受影响!
- 畅玩3A、能装Windows和Linux!国产处理器KX-7000测评来了,性能如何?
- 国产CPU对比:6大处理器自主可控程度大揭秘
- 如何查看显卡型号和性能参数的详细步骤?快速了解显卡配置和性能指标
- NVIDIA RTX 5090新一代旗舰卡大曝光:接口、功耗巨变 售价猛涨
- 微软新专利展示折叠屏Surface Phone正面形态
- AMD AI9 365处理器掌机全新登场,性能强劲,售价仅需7699元
- 微软总裁:“中国正在科技领域赶上西方”:科技领域中国崛起的趋势如何助力实现领先地位?
- 极摩客EVO-X1迷你主机上新:HX 370处理器,定价5299元,性价比超高!
系统资讯推荐
- 1 如何查看显卡型号和性能参数的详细步骤?快速了解显卡配置和性能指标
- 2 AMD AI9 365处理器掌机全新登场,性能强劲,售价仅需7699元
- 3 微软总裁:“中国正在科技领域赶上西方”:科技领域中国崛起的趋势如何助力实现领先地位?
- 4 极摩客EVO-X1迷你主机上新:HX 370处理器,定价5299元,性价比超高!
- 5 AMD全球裁员上千人,市场“吓坏”!英伟达能否赶上?
- 6 Windows 11今起可以直接运行安卓APP了,微软操作系统迎来重大更新
- 7 涉及1000名员工!AMD宣布全球裁员4%,中国区也受影响,员工如何应对?
- 8 英伟达RTX 50系列显卡蓄势待发,40系列步入清仓阶段2022最新
- 9 摩尔线程启动IPO上市辅导,中国英伟达估值255亿!
- 10 AMD良心! ZEN6锐龙不换接口,性能强大,不用担心接口兼容问题
win10系统推荐
系统教程推荐
- 1 win10安装以何种方式进行设置 win10怎么装双系统
- 2 传统桌面win11桌面 Win11传统桌面界面如何恢复
- 3 win11用户管理员权限在哪儿 Win11管理员权限如何设置
- 4 win11麦的声音特别小 win11麦克风声音小怎么解决
- 5 windows电脑如何复制粘贴 笔记本电脑复制文件的方法
- 6 win11网络打印机搜不到 打印机缺墨怎么办
- 7 怎么设置win11熄屏时间 win11电脑熄屏时间设置方法步骤
- 8 win11安全中心防病毒威胁怎么关 win11病毒防护技巧
- 9 win11查看当前分辨率 电脑分辨率如何查询
- 10 win11系统怎么改显示器长亮 电脑屏幕常亮设置方法